问题汇总
WSL2 如何一键设置代理
新建配置脚本 .proxyrc
1 | nano ~/.proxyrc |
内容,端口号换成自己的v2rayn监听的端口
1 | !/bin/bash |
使用生效
1 | source .proxyrc |
Hexo文章如何置顶
hexo-generator-index-pin-top是一个文章置顶功能插件,在置顶之外实现文章按发表时间倒序功能,该插件用于替换hexo-generator-index插件
卸载系统自带的排序插件
1 | npm uninstall hexo-generator-index |
添加替代插件
1 | npm install hexo-generator-index-pin-top --save |
使用,添加top:xxx,数值越大越靠前:
1 | --- |
WSL 子系统如何默认root登入
进入目录:%HOMEPATH%\AppData\Local\Microsoft\WindowsApps\CanonicalGroupLimited.Ubuntu_79rhkp1fndgsc
黑色部分为Ubuntu子系统的文件夹,其他系统应该都差不多
执行命令:
1 | ubuntu.exe config --default-user root |
重启WSL子系统即可看到效果,默认登入的就是root账户了。
如何删除Windows资源管理器左侧计算机同级目录
打开注册表
直接按CTRL+F 搜索Synology Drive
在NameSpace 中会看到搜索结果,直接删除即可。
IntelliJ IDEA 控制台乱码
IntelliJ IDEA 控制台乱码问题可以通过以下方式解决:
方法一:
1. 打开IntelliJ IDEA
2. 点击菜单Help,选择Edit Custom VM Options
3. 在打开的文件中,找到文件的末尾,添加一行-Dfile.encoding=UTF-8
4. 再次启动IntelliJ IDEA,查看编码是否已经修复
方法二:
1. 打开IntelliJ IDEA
2. 点击菜单File -> Settings(或者使用快捷键Ctrl+Alt+S)
3. 在打开的对话框中,选择Editor -> File Encodings
4. 在右侧,Global Encoding和Project Encoding选择UTF-8,Default encoding for properties files选择UTF-8
5. 确认后,再次启动IntelliJ IDEA,查看编码是否已经修复
方法三:
在Run/Debug Configurations -> Configuration -> VM options 里面加上 -Dfile.encoding=UTF-8 参数。
注意: 以上更改可能需要重启IntelliJ IDEA才能生效。
docker 启动报错 library initialization failed - unable to allocate file descriptor table - out of memory
docker 启动报错
1 | library initialization failed - unable to allocate file descriptor table - out of memory |
1.报错日志
1 | library initialization failed - unable to allocate file descriptor table - out of memory/cm-server/aiboxCloud-web/boot/entrypoint.sh: line 2: 6 Aborted (core dumped) java -Xms1024m -Xmx2048m -jar -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/cm-server/logs/gc-%t.log -Dfile.encoding=utf-8 -Duser.timezone=GMT+8 -XX:MaxDirectMemorySize=512m .runtime/modular-bpm-runtime.jar |
2.原因
(1) LimitNOFILE=infinity 虽然是不限制,但是在systemctl版本小于234的时候不生效,查看systemctl版本:systemctl –version
(2) docker容器的ulimit太小了,有文档说太大也不行
3.解决方法
解决方法1
修改/lib/systemd/system/docker.service文件
1 | LimitCORE=infinity |
改成
1 | LimitCORE=65535 |
重启docker服务
1 | systemctl daemon-reload && systemctl restart docker |
解决方法2
问题:因运存不足无法给进程分配更多的文件句柄数而异常退出
原运行指令
1 | docker run --name sentinel -p 8079:8858 -td bladex/sentinel-dashboard |
改为
1 | docker run --ulimit nofile=1024 --name sentinel -p 8079:8858 -td bladex/sentinel-dashboard |
解决方法3
在 /etc/systemd/system/ 目录下, 创建 docker.service.d 目录
进入该目录,创建一个文件,名为 docker.conf
在文件中加入以下配置:
1 | [Service] |
Kotlin JSON反序列化使用枚举作为类型时参数解析使用的是下标而不是实际的值问题
在 Kotlin 中使用 JSON.parseObject 方法将 JSON 字符串解析为一个对象时,如果该对象包含枚举类型,并且 JSON 中的枚举值是以整数下标表示的,而不是枚举名称,那么需要确保枚举类的定义和解析逻辑能够正确处理这种情况。
假设你有一个 DuYunDto 类,其中包含枚举类型的字段,例如:
1 | data class DuYunDto( |
在这种情况下,你需要自定义枚举的解析逻辑。可以使用 @JsonCreator 注解和一个静态方法来实现自定义解析:
1 | import com.alibaba.fastjson.JSON |
在这个例子中:
MyEnum枚举类包含一个value属性来表示对应的整数值。- 使用
@JsonCreator注解和fromValue静态方法来实现自定义解析逻辑,确保 JSON 中的整数值可以正确转换为枚举值。 @JsonValue注解和toValue方法用于将枚举值转换回整数值,以便在序列化时使用。
这样,JSON.parseObject 方法在解析 JSON 字符串时会使用自定义的解析逻辑,将整数值正确转换为对应的枚举值。
hyper-v 建立外部虚拟交换机后宿主机上传文件到其他机器及云盘变得非常慢
在Hyper-V中创建外部虚拟交换机后宿主机上传速度变慢,通常与虚拟交换机对物理网卡功能的干扰有关。下面表格汇总了可能的解决方法,你可以逐一尝试。
| 调整类别 | 具体设置项 | 操作建议/目标效果 |
|---|---|---|
| 禁用卸载功能 | 大型发送卸载 (LSO) | 在物理网卡和Hyper-V创建的虚拟网卡 (vEthernet) 上,将IPv4/IPv6的LSO设置为禁用。这是最常见有效的方案。 |
| TCP/UDP校验和卸载 | 如果禁用LSO效果不佳,可尝试在PowerShell中禁用校验和卸载 | |
| 调整高级功能 | 接收段合并 (RSC) | 在物理网卡和虚拟网卡上,禁用IPv4/IPv6的RSC |
| 虚拟机队列 (VMQ) | 特别是在使用某些品牌(如Broadcom)网卡时,在物理网卡的属性中禁用VMQ可能改善性能 | |
| 数据包处理 | 数据包合并 | 如果宿主机使用WiFi联网,在物理无线网卡上禁用此选项 |
💻如何修改这些设置
- 右键点击“开始”按钮,选择“设备管理器”。
- 展开“网络适配器”部分。
- 找到你的物理网卡(如 Intel, Killer, Realtek 等)和名为“vEthernet”的Hyper-V虚拟网卡。
- 右键点击每个网卡,选择“属性”,切换到“高级”选项卡。
- 在属性列表中,查找上述提到的功能(如 Large Send Offload, Recv Segment Coalescing, Packet Coalescing 等),将其值设置为 Disabled。
hyper-v 增强会话问题
- 卡在登录界面
原因:Windows hello的Bug
解决:进入虚拟机,打开 设置 -> 账户 -> 登录选项,找到其他设置下的:为了提高安全性,仅允许对此设备上的Microsoft帐户使用WindowsHello登录(推荐) 选项,选择关闭即可解决问题
- 启用或禁用增强会话
方法 1:通过 Hyper-V 设置(全局)
按照以下步骤,在 Hyper-V 设置中为所有用户启用或禁用增强会话模式:
打开「Hyper-V 管理器」,在左侧的导航栏中选择你的计算机名称。
在右侧的「操作」栏中点击「Hyper-V 设置」。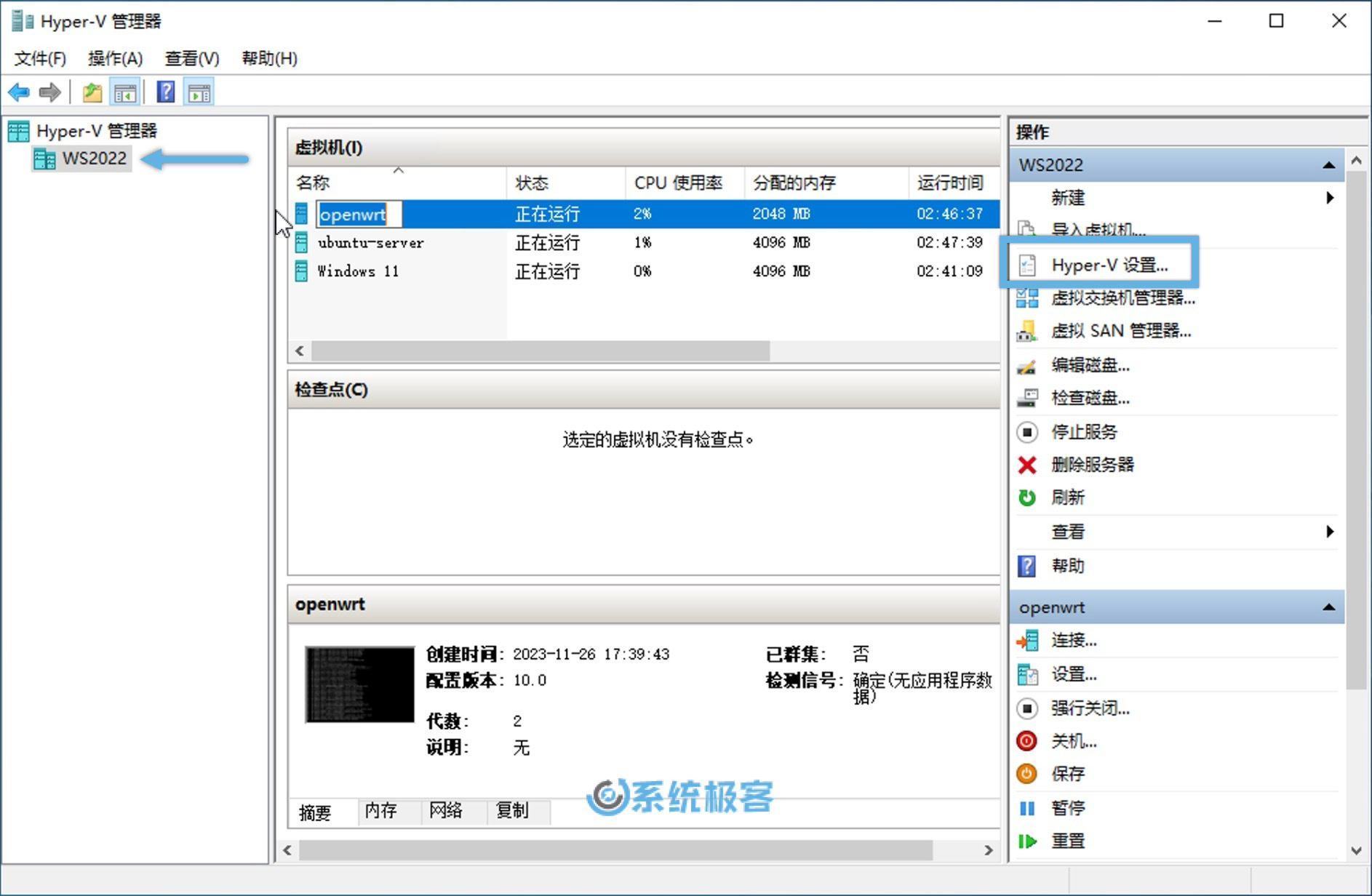
在左侧的导航栏中,点击「服务器」部分下的「增强会话模式策略」选项卡,然后勾选「允许增强会话模式」的复选框。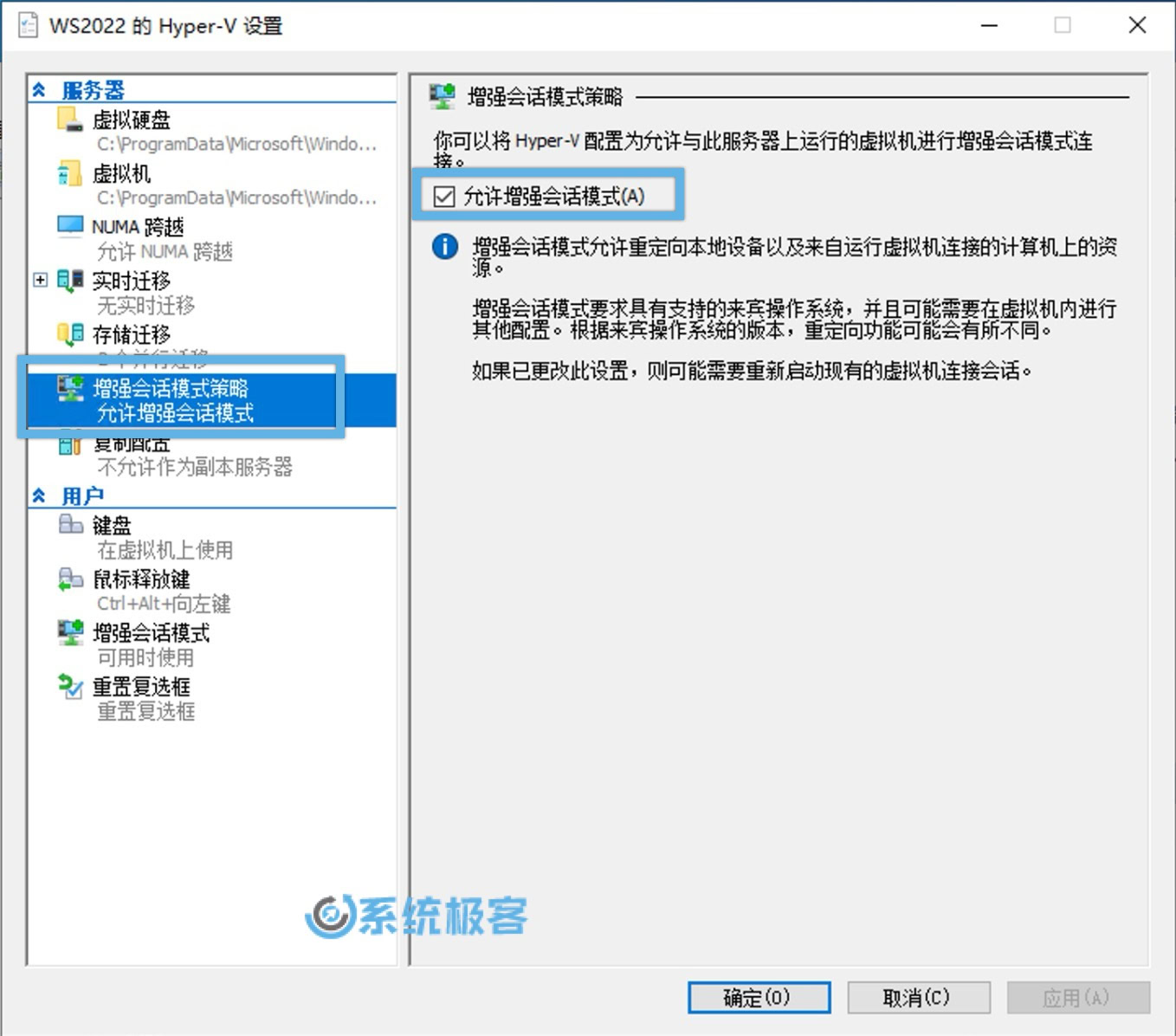
然后点击「确定」按钮。
方法 1:在 Hyper-V 中,可以通过 VM 窗口中的「查看」菜单快速启用或禁用增强会话模式。